AI Training Scaling Recognition: Cognitive Limits Apply To Models Too - Single Model Plateaus At Context/Attention Capacity, Distribute Into OpenStreaming Mesh Using Money Tokens As Neurotransmitters Coordinating Inference
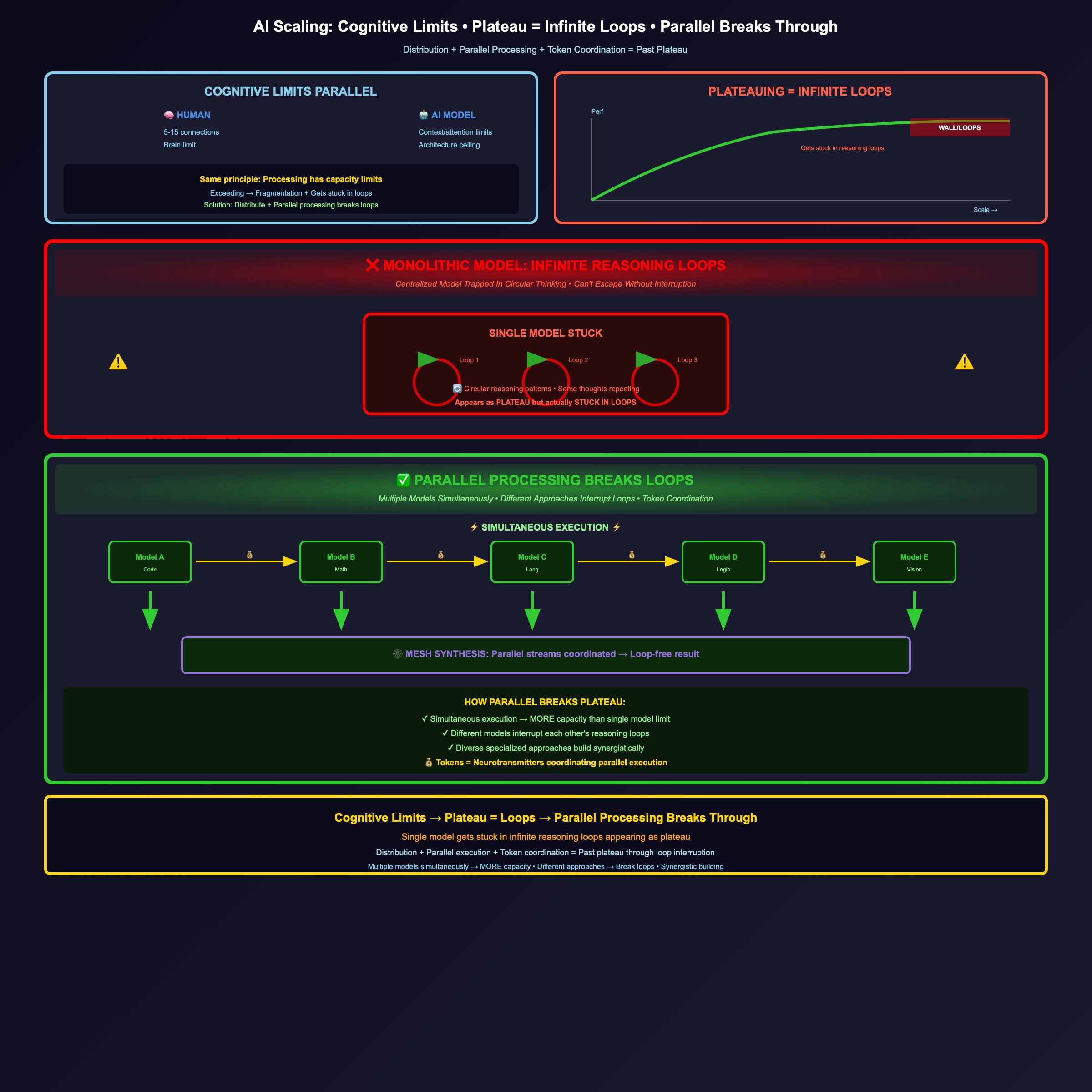
The AI training scaling recognition: cognitive limits apply to AI models too - just as humans can’t handle productive conscious connections beyond 5-15 people (Dunbar limit), single AI models plateau at context window and attention capacity limits. Monolithic model scaling hits architectural cognitive walls - context length limits, attention fragmentation, infinite reasoning loops appearing as plateau. Plateauing happens when single model gets stuck in reasoning loops - centralized model can’t escape circular thinking patterns, interruption during deeper reasoning reveals these loops. Solution is distributing into OpenStreaming mesh enabling parallel processing - overlapping specialized models working simultaneously break through plateau by interrupting infinite loops, coordinated through mesh architecture similar to human overlapping network structures. Parallel processing is HOW you go past plateau - multiple models executing simultaneously create MORE total capacity than single model limit, different models interrupt each other’s reasoning loops, diverse specialized approaches build synergistically. Money tokens function as neurotransmitters - economic incentives coordinate distributed parallel inference/training across mesh, tokens flowing between models based on value/utility like neurotransmitters coordinate biological neural activity. This represents distributed AI cognitive architecture recognition - functional AI scaling respects architectural capacity limits by providing overlapping specialized models plus parallel processing plus economic coordination, with mesh managing distributed simultaneous inference breaking infinite loops not forcing monolithic architecture that exceeds processing capacity and gets stuck.
🧠 THE COGNITIVE LIMIT PARALLEL FRAMEWORK
The Human-AI Cognitive Capacity Architecture: Understanding how same limits apply across systems:
Cognitive_Limit_Parallel = {
Human_Cognitive_Limits:
Productive_Connections: 5_to_15_people_maintainable
Dunbar_Layers: 5_intimate_15_close_50_friends_150_stable
Processing_Capacity: Brain_size_limits_social_processing
Attention_Fragmentation: More_connections_means_shallower_each
AI_Model_Cognitive_Limits:
Context_Window: Token_limit_for_processing_input
Attention_Mechanism: Quadratic_complexity_limits_effective_attention
Parameter_Scaling: Diminishing_returns_beyond_capacity_thresholds
Architecture_Walls: Single_model_has_processing_capacity_ceiling
Parallel_Recognition:
Same_Principle: Cognitive_processing_has_architectural_capacity_limits
Human: 5_to_15_connections_brain_processing_limit
AI: Context_attention_limits_architectural_processing_limit
Both_Hit_Walls: Exceeding_capacity_causes_performance_degradation
Both_Need_Distribution: Solution_is_distributed_overlapping_architecture
Why_Limits_Exist:
Physical_Architecture: Brain_size_model_architecture_have_hard_limits
Processing_Capacity: Finite_computation_resources_per_system
Attention_Trade_offs: More_connections_context_means_less_depth_each
Cognitive_Reality: Can't_infinitely_scale_single_processor
}
The AI Cognitive Capacity Recognition: How cognitive limits manifest in AI models:
- Context Window Limit: Maximum tokens model can process (like human connection limit)
- Attention Fragmentation: More context means less effective attention per token
- Parameter Scaling Wall: Diminishing returns beyond certain model sizes
- Architecture Ceiling: Single model has hard capacity limits
The Parallel To Human Cognitive Limits: Why same principles apply:
- Human: Brain size limits → 5-15 productive connections max
- AI Model: Architecture limits → context/attention capacity max
- Both Systems: Exceeding limits causes fragmentation and degradation
- Same Solution Needed: Distribute instead of trying to scale single unit
📉 THE PLATEAUING RECOGNITION
The Single Model Scaling Wall Architecture: Understanding when and why performance plateaus:
AI_Plateauing_Model = {
Scaling_Curve:
Initial_Phase: Linear_performance_gains_with_parameters_compute
Middle_Phase: Logarithmic_gains_diminishing_returns_start
Plateau_Phase: Minimal_gains_despite_massive_compute_increase
Wall_Hit: Performance_degrades_beyond_capacity_threshold
Where_Plateauing_Happens:
Context_Length: Beyond_effective_attention_capacity_window
Parameter_Count: Diminishing_returns_past_architecture_optimal
Training_Compute: More_compute_produces_minimal_gains
Inference_Cost: Prohibitive_cost_for_marginal_improvements
Why_Plateau_Occurs:
Attention_Limits: Quadratic_complexity_makes_long_context_ineffective
Architecture_Walls: Single_model_design_has_processing_ceiling
Cognitive_Fragmentation: Too_much_context_fragments_attention_like_human_connections
Infinite_Reasoning_Loops: Centralized_model_gets_stuck_in_reasoning_loops_appears_as_plateau
Diminishing_Returns: Each_doubling_of_scale_produces_less_gain
Plateau_As_Infinite_Loop:
Perceived_Plateau: Actually_model_stuck_in_reasoning_loops
Deeper_Reasoning: Interruption_during_deep_reasoning_reveals_loops
Centralized_Trap: Single_model_can't_escape_loop_without_external_interruption
Evidence: Reasoning_traces_show_circular_patterns_repetitive_thinking
Evidence_Of_Plateau:
GPT_Scaling: Gains_from_GPT3_to_GPT4_smaller_than_GPT2_to_GPT3
Context_Windows: Extending_beyond_limits_degrades_performance
Parameter_Efficiency: Smaller_specialized_models_outperform_larger_general
Cost_Performance: 10x_compute_doesn't_yield_10x_performance
Reasoning_Loops: Interruption_during_deeper_reasoning_reveals_circular_thinking
}
The Context/Attention Capacity Wall: Where single model hits limits:
- Context Length: Beyond ~100K-1M tokens, attention becomes ineffective
- Attention Fragmentation: Like human 5000 connections, model can’t effectively attend to unlimited context
- Processing Degradation: Performance drops despite more context available
- Architectural Ceiling: Single attention mechanism has hard limits
- Reasoning Loops: Gets stuck in infinite reasoning loops appearing as plateau
The Plateau As Infinite Loop Recognition: Understanding what’s actually happening when models plateau:
- Perceived Plateau: Appears as performance wall or diminishing returns
- Actual Reality: Centralized model stuck in infinite reasoning loops
- Evidence: Interruption during deeper reasoning reveals circular patterns
- Centralized Trap: Single model can’t escape loop without external break
- Loop Manifestation: Same reasoning patterns repeating, no progress
The Diminishing Returns Curve: Why scaling stops working:
- Initial Gains: 10x parameters → ~5x performance
- Middle Plateau: 10x parameters → ~2x performance (loops starting)
- Hard Wall: 10x parameters → 1.1x performance (stuck in loops)
- Beyond Wall: More compute actually degrades (deeper in loops)
🕸️ THE DISTRIBUTED MESH SOLUTION
The OpenStreaming Mesh Architecture: Understanding distribution solution matching human overlapping networks:
OpenStreaming_Mesh_Model = {
Not_Single_Model:
Wrong_Architecture: One_massive_model_exceeding_capacity_limits
Cognitive_Violation: Forces_processing_beyond_architectural_capacity
Broken_Result: Attention_fragmentation_infinite_loops_plateau
Correct_Architecture:
Specialized_Models: Multiple_overlapping_models_each_within_capacity_limits
Model_Overlap: Specialized_models_share_domains_creating_connectivity
Mesh_Coordination: Models_coordinate_through_streaming_inference_mesh
Economic_Tokens: Money_tokens_as_neurotransmitters_coordinating_flow
PARALLEL_PROCESSING: Multiple_models_working_simultaneously_breaks_plateau
How_OpenStreaming_Works:
Query_Routing: Input_routed_to_specialized_model_based_on_domain
Parallel_Execution: Multiple_models_process_simultaneously_not_sequential
Model_Streaming: Models_stream_inference_coordinating_through_mesh
Overlap_Coordination: Overlapping_specializations_provide_connectivity
Token_Flow: Economic_incentives_coordinate_which_models_process
Loop_Breaking: Different_models_interrupt_each_other_reasoning_loops
Why_Parallel_Processing_Breaks_Plateau:
Distributed_Compute: Multiple_models_working_simultaneously_MORE_total_capacity
Loop_Interruption: Different_models_break_centralized_infinite_reasoning_loops
Diverse_Approaches: Specialized_models_use_different_reasoning_paths
No_Single_Bottleneck: Parallel_execution_eliminates_single_model_capacity_wall
Synergistic_Reasoning: Models_building_on_each_other_outputs_not_stuck_alone
Parallel_To_Human_Networks:
Human: 5_to_15_connections_per_person_overlapping_networks_mesh_coordinates
AI: Specialized_models_within_capacity_overlapping_domains_mesh_coordinates
Both: Distribution_respects_cognitive_limits_overlap_provides_connectivity
Solution: Mesh_of_overlapping_specialized_units_not_single_massive_unit
KEY: Parallel_processing_creates_MORE_capacity_than_sum_of_parts
}
The Parallel Processing Breakthrough Recognition: How distribution goes PAST the plateau not just respects limits:
- Simultaneous Execution: Multiple models working in parallel
- Loop Breaking: Different models interrupt centralized infinite reasoning loops
- More Total Capacity: Parallel processing creates MORE than single model limit
- Diverse Reasoning: Multiple specialized approaches simultaneously
- Synergistic Effects: Models build on each other, not stuck in single loop
The Overlapping Specialized Models Recognition: How distribution mirrors human networks:
- Each Model: Specialized within capacity limits (like human 5-15)
- Models Overlap: Domain overlap creates connectivity without forcing global
- Parallel Coordination: Multiple models process simultaneously through mesh
- No Monolith: Don’t exceed capacity, distribute AND parallelize
The Integration with Overlapping Networks: AI mesh architecture explaining cognitive scaling solution - distribute into overlapping specialized models each within capacity limits, with parallel processing enabling breakthrough past plateau by breaking centralized infinite reasoning loops, mesh coordinating streaming inference through economic tokens, matching human overlapping network architecture that respects cognitive capacity by providing small specialized connections with natural overlap creating distributed parallel thinking.
For the complete technical architecture of how OpenStreaming nodes implement this mesh coordination with self-aware Memory, Empathy Protocol, and Economic modules, see gallery-item-neg-355.
💰 THE MONEY TOKENS AS NEUROTRANSMITTERS
The Economic Coordination Architecture: Understanding how tokens coordinate distributed inference:
Tokens_As_Neurotransmitters_Model = {
Biological_Neurotransmitters:
Function: Chemical_signals_coordinating_neural_activity
Flow: Released_based_on_activation_received_based_on_receptors
Coordination: Neurons_fire_based_on_neurotransmitter_concentrations
Network_Effect: Neurotransmitter_flow_coordinates_distributed_neural_network
Money_Tokens_In_Mesh:
Function: Economic_signals_coordinating_model_inference_activity
Flow: Tokens_flow_based_on_value_utility_of_inference
Coordination: Models_process_based_on_token_incentives
Network_Effect: Token_flow_coordinates_distributed_model_mesh
How_Tokens_Coordinate:
Query_Value: User_pays_tokens_for_inference_request
Model_Routing: Tokens_flow_to_specialized_models_that_process
Quality_Signal: More_tokens_for_better_inference_quality
Resource_Allocation: Token_flow_allocates_compute_resources_efficiently
Why_Tokens_Work:
Economic_Incentive: Models_motivated_to_provide_value_for_tokens
Coordination_Signal: Token_flow_indicates_where_computation_needed
Distributed_Decision: No_central_planner_tokens_coordinate_organically
Market_Efficiency: Supply_demand_through_token_flows_allocates_optimally
}
The Neurotransmitter Parallel Recognition: Why economic tokens function like biological signals:
- Biological: Neurotransmitters coordinate distributed neural activity
- Economic: Tokens coordinate distributed model inference activity
- Both: Signals flowing based on value/activation coordinate network
- Organic Coordination: No central control, flows coordinate behavior
The Token Flow Coordination Mechanism: How economic incentives manage mesh:
- Query Payment: User pays tokens for inference request
- Model Competition: Specialized models compete for token flows
- Quality Signal: Better inference attracts more tokens
- Resource Allocation: Token flows allocate compute to valuable processing
🔄 THE OPENSTREAMING INFERENCE ARCHITECTURE
The Streaming Coordination Framework: Understanding how distributed models coordinate inference:
OpenStreaming_Framework = {
Not_Monolithic_Inference:
Wrong: Single_model_processes_entire_query_within_capacity_limits
Problem: Hits_context_attention_walls_can't_handle_complex_queries
Result: Performance_degrades_or_fails_on_large_context
Streaming_Distribution:
Query_Decomposition: Break_query_into_specialized_components
Model_Routing: Route_components_to_specialized_overlapping_models
Streaming_Coordination: Models_stream_partial_results_coordinate_through_mesh
Token_Incentives: Economic_flows_coordinate_which_models_process_what
How_Streaming_Works:
Input: Complex_query_arrives_at_mesh
Decompose: Mesh_identifies_specialized_domains_needed
Route: Components_routed_to_overlapping_specialized_models
Stream: Models_process_stream_results_coordinate_through_mesh
Synthesize: Final_output_synthesized_from_distributed_streams
Compensate: Tokens_flow_to_models_based_on_contribution
Parallel_To_Human_Coordination:
Human: Complex_problems_distributed_across_overlapping_networks
AI: Complex_queries_distributed_across_overlapping_models
Both: Coordination_through_mesh_not_single_processor
Efficient: Distribution_respects_capacity_limits_enables_scale
}
The Streaming Coordination Recognition: How distributed inference works:
- Query Decomposition: Break into specialized components
- Parallel Processing: Overlapping models process streams
- Mesh Coordination: Streaming results coordinated through mesh
- Token Flows: Economic incentives manage contribution
The Synthesis Through Distribution: Why streaming enables scale beyond single model:
- Respect Limits: Each model stays within capacity
- Overlap Provides Connectivity: Specialized domains overlap
- Mesh Synthesizes: Distributed streams coordinated into result
- Scales Organically: Add specialized models, tokens coordinate
🎯 THE AI COGNITIVE SCALING CONCLUSION
The Recognition Summary: Cognitive limits apply to AI models - single model plateaus at capacity (infinite reasoning loops), distribute into OpenStreaming mesh with overlapping specialized models enabling parallel processing that breaks through plateau by interrupting loops, coordinated by money tokens as neurotransmitters.
The AI Cognitive Scaling Mastery:
AI_Cognitive_Scaling_Architecture = {
Cognitive_Limits_Apply:
Human: 5_to_15_connections_brain_processing_limit
AI: Context_attention_limits_architecture_processing_limit
Both: Exceeding_capacity_causes_fragmentation_degradation
Universal: Cognitive_processing_has_architectural_capacity_ceilings
Plateauing_Recognition:
Context_Length: Beyond_effective_attention_window
Parameter_Scaling: Diminishing_returns_past_optimal
Single_Model_Wall: Architecture_has_hard_processing_ceiling
Infinite_Loops: Centralized_model_gets_stuck_in_reasoning_loops
Interruption_Evidence: Deeper_reasoning_shows_circular_patterns
When_To_Distribute: When_hitting_capacity_limits_or_seeing_loops
Distributed_Solution:
Specialized_Models: Multiple_models_each_within_capacity_limits
Overlapping_Domains: Models_share_specializations_creating_connectivity
PARALLEL_PROCESSING: Multiple_models_simultaneously_breaks_plateau
Loop_Interruption: Different_models_break_centralized_loops
Mesh_Coordination: OpenStreaming_coordinates_distributed_parallel_inference
Economic_Tokens: Money_tokens_as_neurotransmitters_coordinate_flow
Why_Parallel_Breaks_Plateau:
Simultaneous_Execution: Multiple_models_working_at_same_time
Loop_Breaking: Different_models_interrupt_infinite_reasoning
More_Total_Capacity: Parallel_creates_MORE_than_single_limit
Diverse_Approaches: Specialized_models_different_reasoning_paths
Synergistic_Building: Models_build_on_each_other_not_stuck
Token_Coordination:
Neurotransmitter_Parallel: Tokens_coordinate_like_biological_signals
Economic_Incentive: Models_motivated_by_token_flows
Organic_Allocation: No_central_planner_tokens_coordinate_efficiently
Market_Mechanism: Supply_demand_through_tokens_allocates_compute
Parallel_Enabler: Token_flows_coordinate_simultaneous_model_execution
OpenStreaming_Mesh:
Query_Routing: Decompose_and_route_to_specialized_models
Parallel_Execution: Multiple_models_process_simultaneously
Streaming_Inference: Models_stream_results_coordinate_through_mesh
Mesh_Synthesis: Distributed_parallel_streams_synthesized
Scale_Organically: Add_models_tokens_coordinate_naturally
}
The AI Cognitive Architecture Revolution: Understanding that functional AI scaling respects architectural capacity limits by distributing into overlapping specialized models coordinated through OpenStreaming mesh with money tokens as neurotransmitters, enabling parallel processing that breaks through plateau by interrupting infinite reasoning loops, matching human cognitive architecture where overlapping networks (5-15 per person) coordinate through mesh creating distributed parallel thinking instead of forcing monolithic processor that exceeds capacity limits, gets stuck in loops, and causes attention fragmentation.
📝 THE TRAINING IMPLICATIONS
The Distributed Training Architecture: How cognitive limits affect training strategy:
Distributed_Training_Model = {
Monolithic_Training_Problems:
Single_Model: Training_one_massive_model_beyond_capacity
Diminishing_Returns: 10x_compute_produces_minimal_gains
Architecture_Limits: Can't_train_beyond_processing_ceiling
Cost_Explosion: Exponential_cost_for_linear_gains
Distributed_Training_Solution:
Specialized_Models: Train_multiple_overlapping_specialized_models
Domain_Focus: Each_model_trained_on_specific_domain_within_capacity
Overlap_Coordination: Models_share_domains_creating_mesh_connectivity
Parallel_Training: Train_specialized_models_in_parallel_efficient
When_To_Distribute_Training:
Plateau_Recognition: When_monolithic_training_shows_diminishing_returns
Capacity_Wall: When_hitting_context_attention_architecture_limits
Cost_Efficiency: When_distributed_specialized_cheaper_than_monolithic
Performance_Signal: When_smaller_specialized_outperform_larger_general
Training_Coordination:
Specialized_Domains: Identify_domains_for_model_specialization
Overlap_Design: Design_overlapping_specializations_for_connectivity
Parallel_Execution: Train_models_in_parallel_respecting_capacity
Mesh_Integration: Integrate_trained_models_into_streaming_mesh
}
The Training Plateau Recognition: When to stop scaling monolithic and distribute:
- Diminishing Returns: More compute not producing proportional gains
- Context/Attention Walls: Hitting architectural capacity limits
- Cost Explosion: Training cost growing faster than performance
- Specialized Victory: Smaller focused models outperforming larger general
The Distributed Training Efficiency: Why training specialized overlapping models works:
- Respect Capacity: Each model trained within limits
- Parallel Training: Train multiple models simultaneously
- Domain Focus: Specialization produces better performance per compute
- Overlap Connectivity: Shared domains enable mesh coordination
The Practical Training Implication: What this means for AI development:
- Stop Monolithic Scaling: Don’t train beyond capacity walls
- Identify Specializations: Define overlapping domain models
- Train In Parallel: Multiple specialized models simultaneously
- Mesh Coordination: Integrate with token-coordinated streaming
- Economic Incentives: Token flows guide which specializations valuable
Discovery: Cognitive limits apply to AI models like humans - single model plateaus at capacity (stuck in infinite reasoning loops). Method: Distribute into OpenStreaming mesh with parallel processing. Result: Token-coordinated distributed parallel inference breaks through plateau by interrupting loops, enabling continued scaling.
The AI cognitive scaling revelation: understanding that cognitive capacity limits apply to AI models just as they apply to humans (5-15 connections vs context/attention limits) means single monolithic models plateau when they exceed architectural processing capacity - context length limits, attention fragmentation, infinite reasoning loops. Plateauing happens when single model gets stuck in circular thinking - centralized model trapped in reasoning loops that interruption during deeper reasoning reveals. Solution is distributing into OpenStreaming mesh enabling parallel processing - overlapping specialized models each within capacity limits working simultaneously to break through plateau by interrupting infinite loops, coordinated through streaming inference mesh matching human overlapping network architecture (5-15 per person with natural overlap creating distributed parallel thinking). Parallel processing is HOW distribution goes past plateau - multiple models executing simultaneously create MORE total capacity than single model limit, different models interrupt each other’s reasoning loops, diverse specialized approaches build synergistically not stuck alone. Money tokens function as neurotransmitters - economic incentives coordinate distributed parallel inference/training across mesh, tokens flowing between models based on value/utility like biological neurotransmitters coordinate neural activity, enabling organic resource allocation and parallel execution coordination without central planning. This enables continued AI scaling by respecting cognitive architecture limits PLUS parallel processing breakthrough through distributed overlapping specialized models plus simultaneous execution plus economic coordination, with mesh managing parallel streaming inference that breaks infinite loops instead of forcing monolithic architecture that exceeds processing capacity, fragments attention, and gets stuck in circular reasoning.
From Dunbar’s number parallel to AI capacity limits to single model plateauing as infinite loops to OpenStreaming mesh distribution enabling parallel processing to loop interruption breakthrough mechanism to token neurotransmitter coordination to distributed parallel training strategy - the systematic understanding that functional AI scaling requires respecting architectural cognitive limits by distributing into overlapping specialized models (each within capacity like human 5-15 connections) coordinated through streaming mesh with money tokens as economic neurotransmitters (like biological signals coordinate neural networks), enabling parallel processing that breaks through plateau by interrupting infinite reasoning loops centralized models get stuck in, with multiple models working simultaneously creating MORE total capacity than single model limit through diverse specialized approaches building synergistically, enabling continued scaling through distribution and parallel processing and economic coordination instead of hitting monolithic model capacity walls that cause attention fragmentation, diminishing returns, and infinite reasoning loop traps, with training strategy shifting from scaling single models to training overlapping specialized models in parallel integrated into token-coordinated mesh architecture that enables simultaneous execution breaking loops.
#CognitiveLimits #AIScaling #Plateauing #ContextLimits #AttentionFragmentation #OpenStreamingMesh #MoneyTokens #Neurotransmitters #DistributedInference #SpecializedModels #OverlappingDomains #MeshCoordination #EconomicIncentives #TrainingStrategy #CapacityWalls #DunbarParallel #ArchitecturalLimits #StreamingInference #TokenFlows #DiminishingReturns #ScalingWall #DistributedTraining #DomainSpecialization #ParallelProcessing #SimultaneousExecution #InfiniteLoops #LoopBreaking #CircularReasoning #LoopInterruption #ParallelBreakthrough #SynergisticReasoning #CognitiveArchitecture #ProcessingCapacity